Inside Angle
From 3M Health Information Systems

About accuracy…part 2
In part one of this blog we focused on recall as it relates to CAC. In today’s post we will start by examining the definition of precision.
With precision, we are concerned with what percentage of codes suggested by the engine are correct. When the auto-suggested codes are correct that’s great, but what happens when they aren’t? A low precision number could mean that there are a lot of codes being presented to the coder that they have to sort through and get out of the way or simply ignore because they’re not actually correct. Sometimes this is referred to as “noise.” Precision can be affected by some of the same factors as recall, although the impact may be felt somewhat differently. For example:
- Not having all of the documents sent to the engine can result in codes not being as specific as they should be. Suppose that a particular diagnosis really requires 2-3 things to be documented in order to be able to produce a code; if only 1 or 2 of those pieces of evidence are in the documents that the engine can consider, then the resulting code may be less specific and the coder will end up manually adjusting for the discrepancy. As with recall, this could occur at a variety of levels within a system: the proper documents not being sent, or the proper sections not set up with documents that ARE being sent.
- Because we’ve talked mostly about configuring documents and sections to make sure all evidence is presented to the engine, it might seem like a logical approach to just “send everything.” If we did that, however, we would likely end up with many auto-suggested codes that are NOT correct. This would occur because the engine would consider non-codeable documents and sections such as nursing notes or speculative but not yet definitive findings and diagnoses. So, when configuring the documentation that will be presented to the engine, it is important that the focus is on those parts of the documents that are relevant to coding.
Precision and recall are complementary measurements that, when used together, give a balanced idea of how well the overall system and configuration are able to provide useful auto-suggested codes. The higher the precision and recall, the more useful the output will be to coders. It’s important that both increase – if only one or the other increases, then the resulting scenario may be confusing or frustrating to coders. Having a high recall but low precision would suggest that the engine is correctly identifying many of the final codes, but is also producing a lot of “noise” or extra codes that the coders are having to deal with. Having a high precision but low recall would indicate that the codes being suggested are very accurate, but in the big picture they’re not helping the coder produce a significant percentage of their final codes.
As with previous posts in this series, I’d like to wrap up by showing some real data. Now that you have a better understanding of what precision and recall mean and some of the factors that influence these measures, you can consider your own environment and processes as you look at this data. The graphs below show the range of precision and recall values across hundreds of facilities for January 2016 – March 2016.
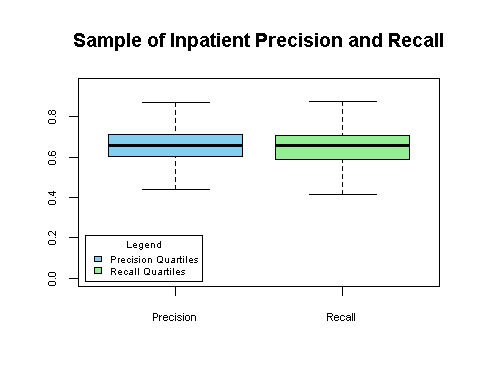
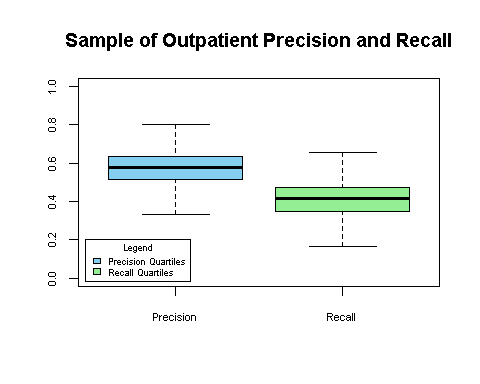
As you look at the measurement ranges, think through your own environment and the factors that might be affecting the performance of your own CAC system. Are your interfaces set up? Are all the right documents being sent? Have these documents been configured? Where do you have handwritten or scanned notes? All of these factors change over time as more documentation becomes electronic, new systems are added, old ones removed, not to mention changes in the underlying technologies such as natural language processing, big data and machine learning that help drive CAC. Refining and improving performance will be an ongoing activity, not a “one and done” event.
Jason Mark is a business intelligence architect with 3M Health Information Systems.


Jason Mark
Manager
Jason Mark is manager, Research & Applied Data Science Lab for 3M Health Information Systems, Inc. Jason has been with 3M HIS since 2005. Prior to his current position, Jason…